Enterprise Playground
Scrape a design system. Fine-tune a model. Generate production UI code. All on one GPU, at $0/token.

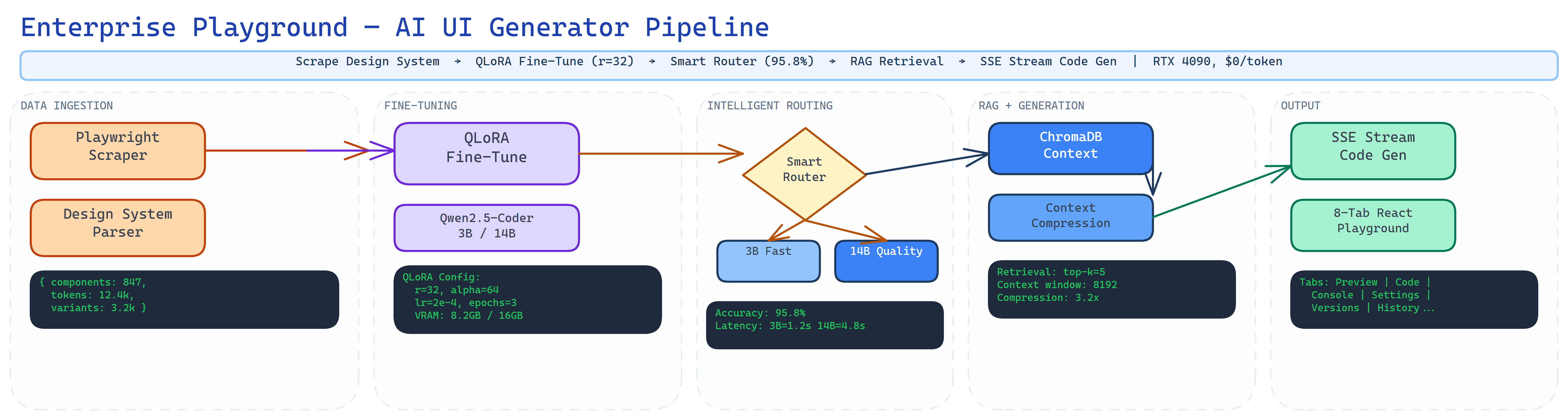
Architecture
“What if your AI didn't just know how to write code — what if it knew your design system?”
The Problem
Enterprise UI development is paradoxically both the most standardized and most tedious work in software. Every company has a design system. Every developer rebuilds the same patterns — data tables, form layouts, dashboard grids — against that system. LLMs can generate generic UI code, but they don't know your specific design tokens, component APIs, or layout conventions.
The Approach
Enterprise Playground closes the loop: Playwright scrapes real banking UIs to build training data, QLoRA fine-tunes a local 14B model on your design system, and the generation engine produces domain-specific UI code using RAG-enhanced context. Two models run simultaneously — a 14B coder for HTML/CSS/JS generation and a 3B model for routing, chat, and context compression.
Key Insight
The dual-model architecture is the secret. The 3B model compresses RAG context by 30-50% before feeding it to the 14B generator — reducing input tokens without losing domain knowledge. Smart routing sends text tasks to the fast 3B model and code generation to the capable 14B model. Total VRAM: 10.5 GB out of 16 GB. One consumer GPU runs the entire pipeline.
How it works
The architecture behind the system.
Design System Scraping
Playwright captures real enterprise UIs — full-page screenshots, structured JSON workflow extraction. Builds training datasets from production design systems.
Dual-Model Inference
qwen2.5-coder:14b for code generation (8.5 GB VRAM) + qwen2.5:3b for routing and compression (2 GB VRAM). Both run simultaneously on a single RTX 4090.
QLoRA Fine-Tuning
LoRA r=32 fine-tuning on scraped design system data. Training loss: 2.85 → 0.42 (85% reduction over 3 epochs). Adapter deploys directly to Ollama.
RAG-Enhanced Generation
ChromaDB + nomic-embed-text retrieves relevant design patterns. 3B compression reduces context tokens by 30-50%. Domain-accurate code without hallucinated APIs.
Smart Routing (95.8%)
Keyword + LLM classifier routes queries to the optimal model. 95.8% routing accuracy. Text questions go fast (3B), code generation goes capable (14B).
8-Tab Observatory
Generate, Gallery, Pipeline, Data & RAG, ML Metrics, Observatory, Agent traces, Embeddings & Storage. Full visibility into every layer of the system.
Built with
