ML Portfolio
Three production-grade ML systems built from scratch in PyTorch — because understanding comes from building, not importing.

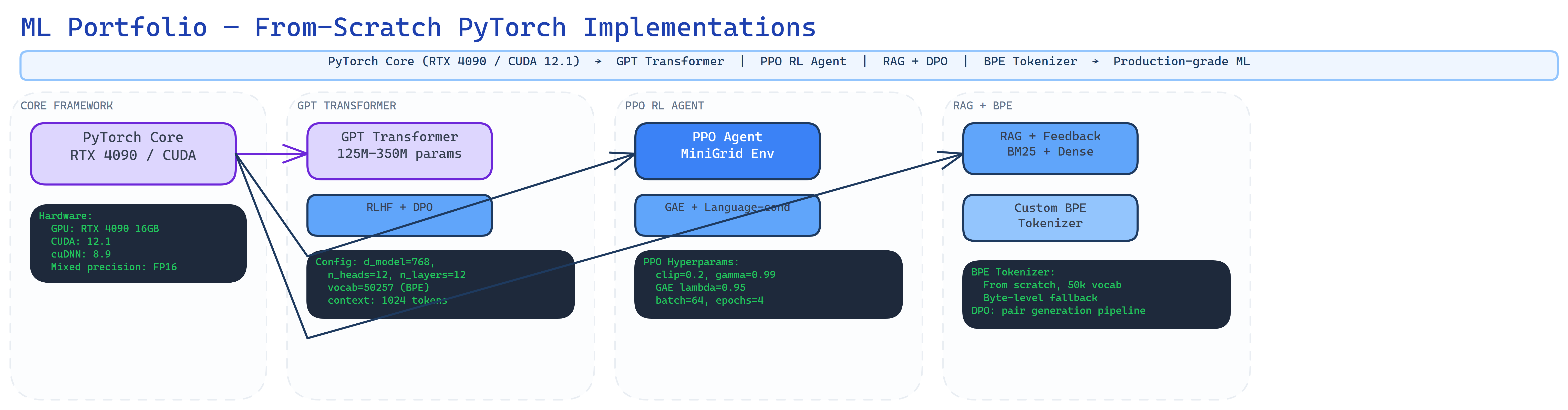
Architecture
“Everyone fine-tunes. Very few build from the ground up.”
The Problem
The ML ecosystem is drowning in wrappers. Engineers pip-install their way to a demo, call it a project, and move on. But when something breaks in production — when the loss curve plateaus, when the reward signal is sparse, when retrieval quality degrades — you need to understand every layer of the stack.
The Approach
I built three complete ML systems from scratch in PyTorch: a GPT transformer with full RLHF alignment pipeline, a PPO game agent that learns from language instructions, and a RAG system that improves through user feedback. No HuggingFace Trainer. No LangChain. Raw tensors, manual backprop, custom training loops.
Key Insight
The gap between a tutorial and production is understanding why each architectural decision exists. BPE tokenization isn't just an algorithm — it's the interface between human language and tensor math. DPO isn't just an alternative to PPO — it removes the reward model bottleneck entirely. These aren't abstractions to learn; they're engineering tradeoffs to internalize.
How it works
The architecture behind the system.
GPT Transformer + RLHF
125M-350M parameter decoder-only transformer with BPE tokenizer from scratch, pre-training, SFT, and DPO alignment. Cosine LR schedule, gradient checkpointing, mixed precision.
PPO Game Agent
Proximal Policy Optimization with GAE and clipped surrogate for MiniGrid. CNN observation encoder + GRU instruction encoder for language-conditioned policies.
RAG with Feedback Learning
Hybrid retriever combining BM25 + dense vectors with Reciprocal Rank Fusion. Feedback collection system generates DPO pairs for continuous improvement.
Custom BPE Tokenizer
Byte-Pair Encoding built from first principles — merge rules, vocabulary building, special tokens. The foundation that makes everything else possible.
Mixed Precision Training
FP16 training with gradient checkpointing to fit larger models in GPU memory. Careful numerical stability for transformer attention and loss computation.
DPO Alignment
Direct Preference Optimization eliminates the reward model from RLHF. Simpler, more stable, and theoretically grounded preference learning.
Built with
