RAG Eval Engine
Most RAG systems guess if they're working. This one measures. Every query is scored for faithfulness, relevance, and hallucination rate.

Architecture
“If you can't measure retrieval quality, you don't have a RAG system — you have a hope system.”
The Problem
RAG is everywhere now. Every startup has a 'chat with your docs' feature. But almost none of them can answer a simple question: is the retrieval actually good? When your system hallucinates, how do you know? When relevance degrades after ingesting 10,000 more documents, who notices?
The Approach
Every query runs through a full evaluation pipeline. Faithfulness, relevance, hallucination rate, context precision, and context recall are scored in real-time using LLM-as-judge and heuristic methods. The system doesn't just retrieve — it proves that its retrievals are trustworthy.
Key Insight
The FACT pattern — Fetch, Assess, Cache, Track — turns evaluation from an afterthought into infrastructure. Semantic caching with a 0.95 similarity threshold catches rephrased queries. Adaptive retrieval auto-tunes the BM25/vector alpha and top-k based on historical scores. The system literally gets better the more you use it.
How it works
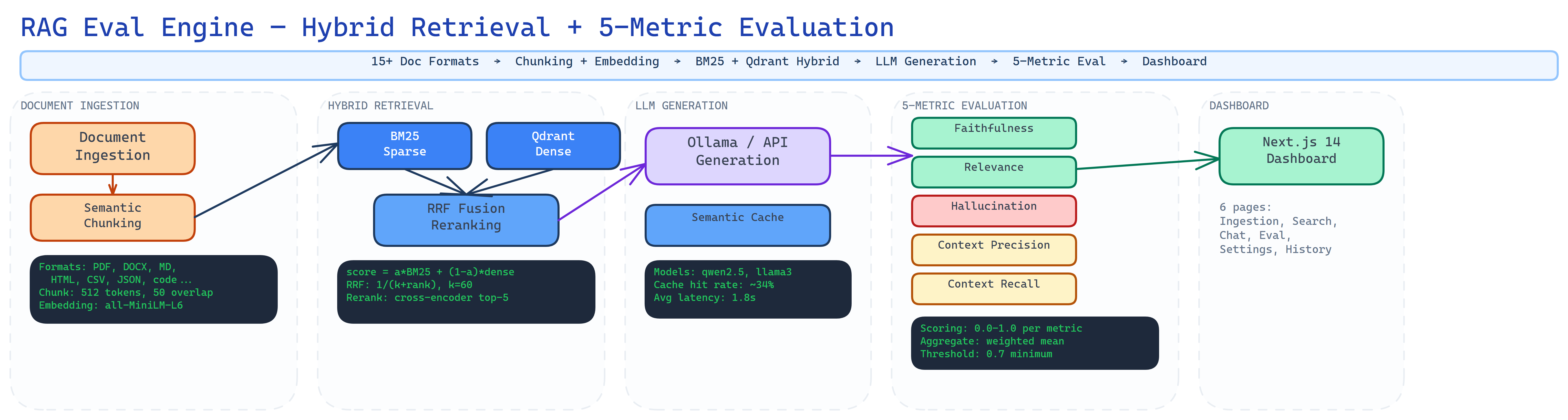
The architecture behind the system.
Hybrid Retrieval
BM25 sparse search + Qdrant vector search fused with Reciprocal Rank Fusion. Configurable alpha lets you dial between keyword precision and semantic recall.
5-Metric Evaluation
Faithfulness, relevance, hallucination rate, context precision, and context recall — scored on every query. LLM-as-judge for nuance, heuristics for speed.
Semantic Query Cache
Embedding-based similarity on Qdrant. Sub-100ms responses on cache hits. Catches semantically identical but differently-worded queries at 0.95 threshold.
15+ Document Formats
PDF, DOCX, TXT, Markdown, and 15+ code formats. Three chunking strategies — fixed-size, recursive, semantic. Token-aware sizing with drag-and-drop upload.
MCP Server Integration
Expose RAG as MCP tools for Claude Code: rag_query, rag_retrieve, rag_ingest_text, rag_collections, rag_metrics. Your knowledge base becomes a tool.
Adaptive Retrieval
Auto-tunes alpha and top-k based on historical evaluation scores. After 10 queries, the system recommends optimal retrieval parameters for your data.
Built with