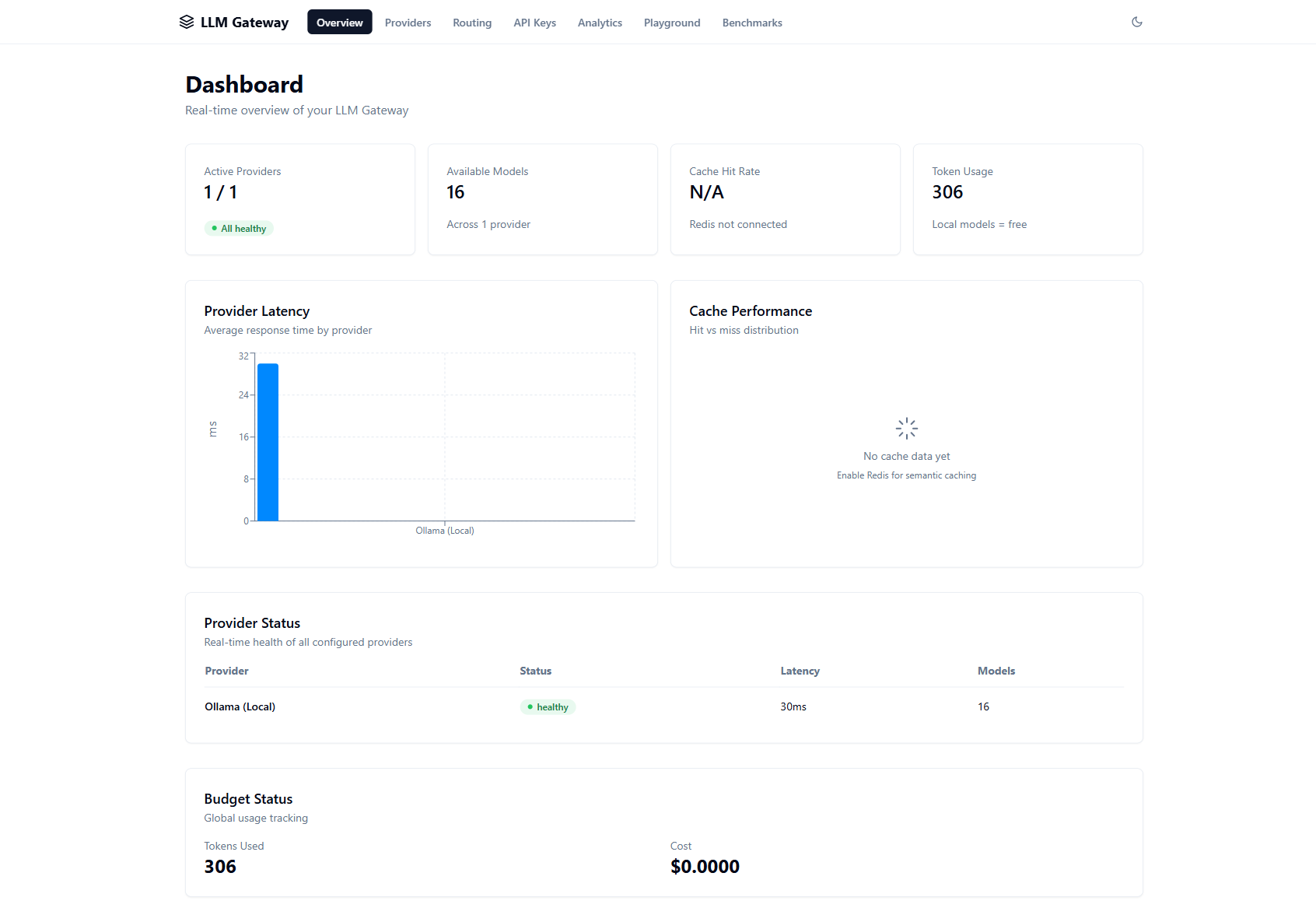
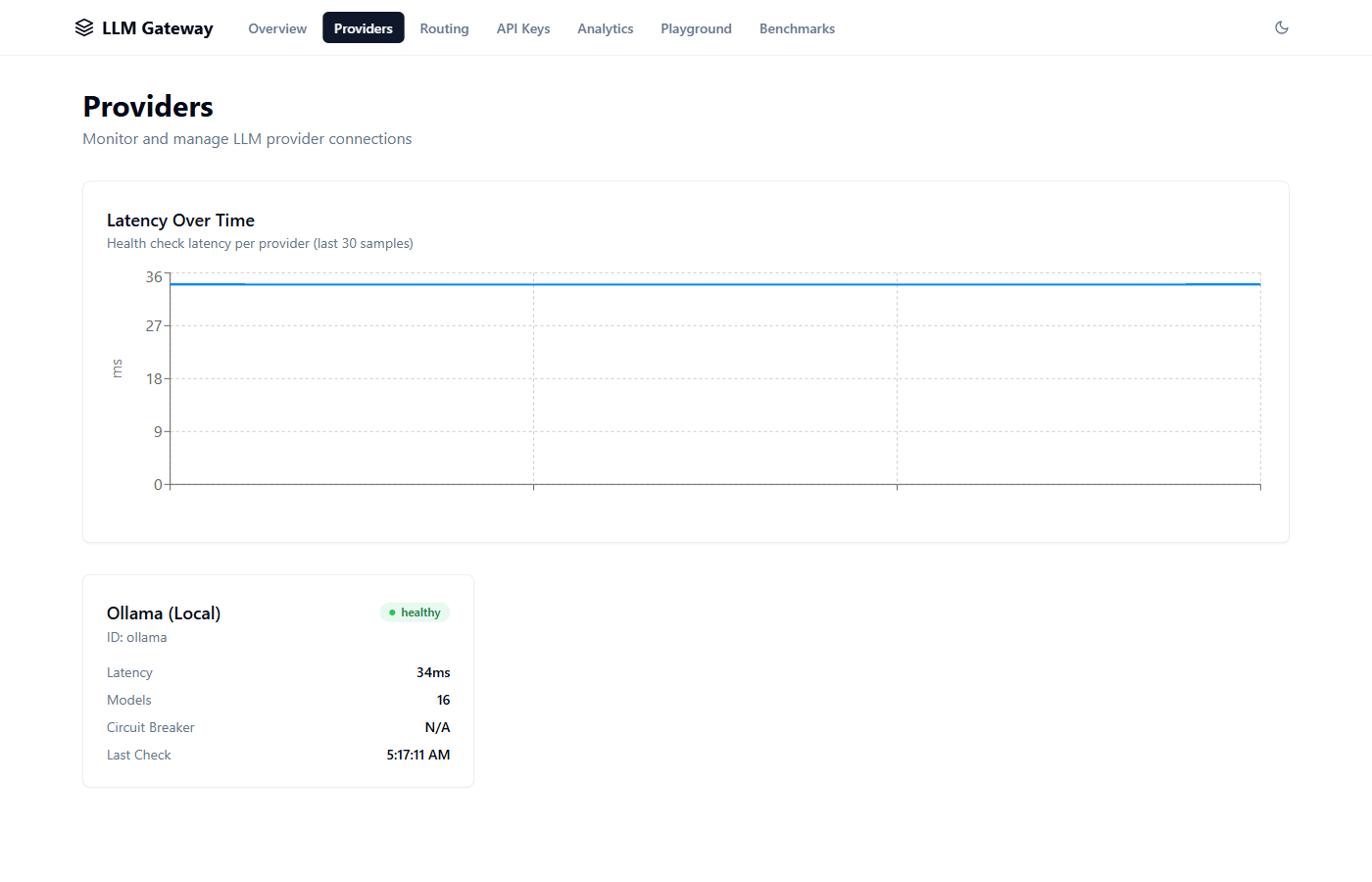
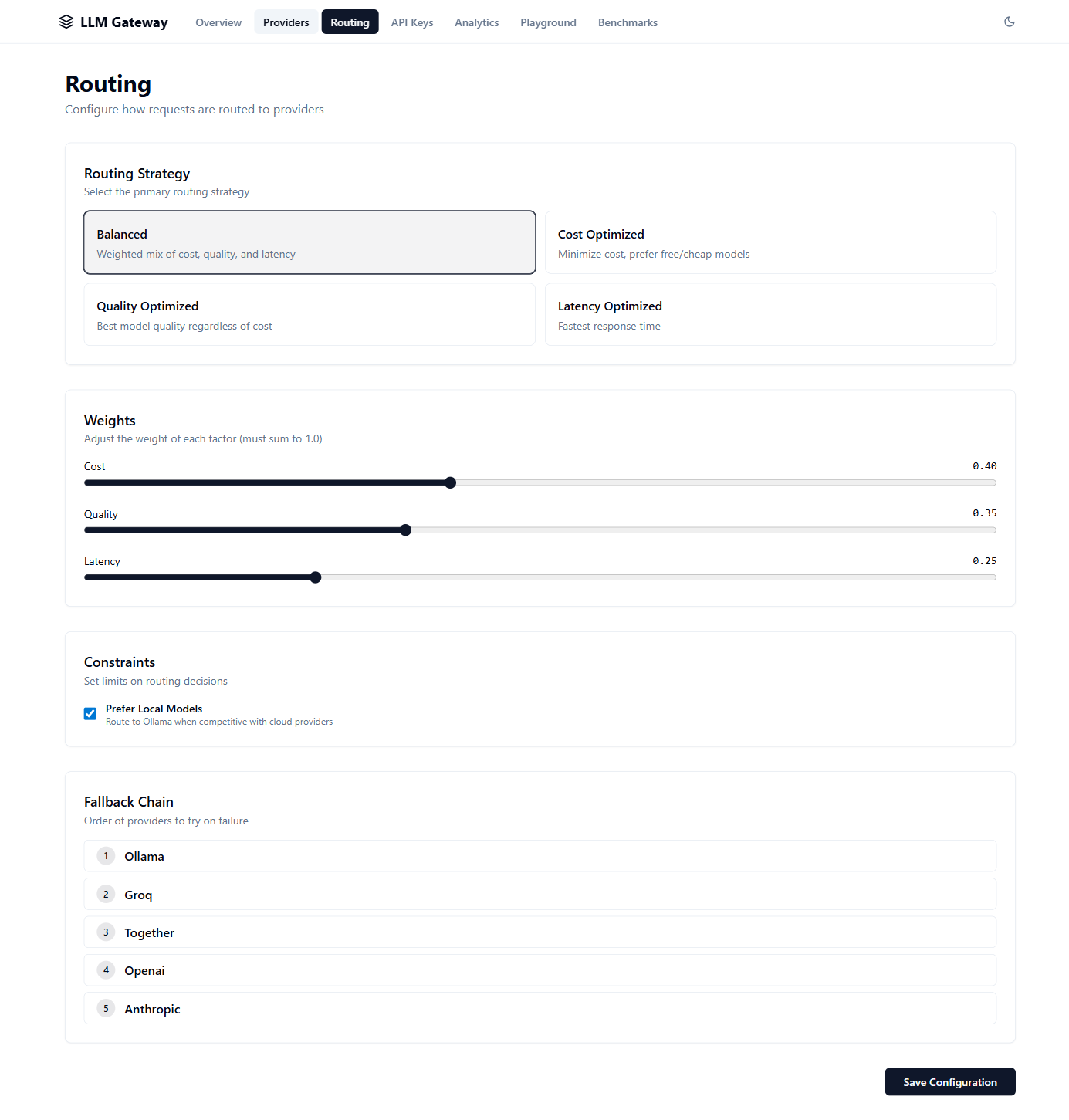
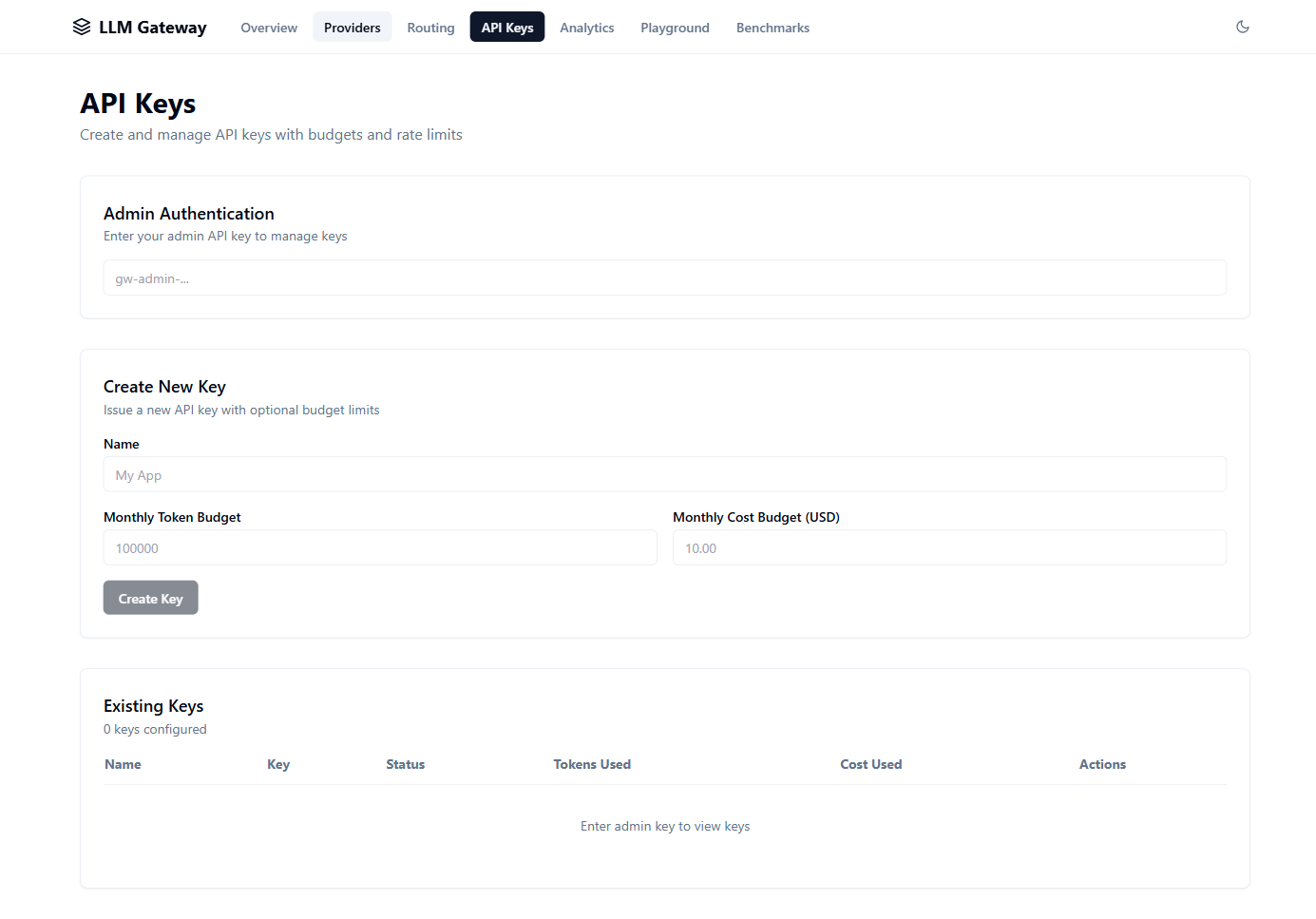
LLM Gateway
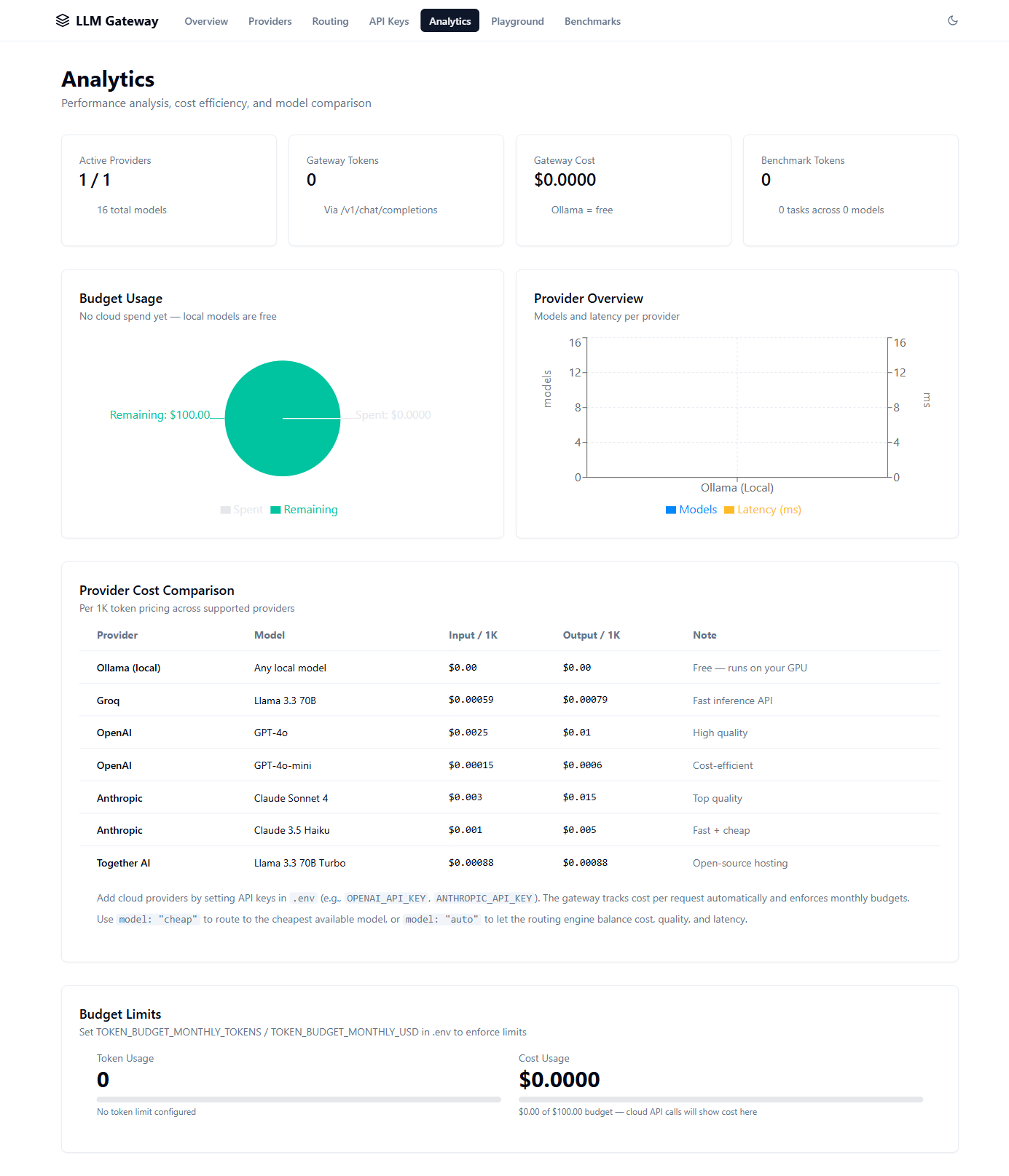
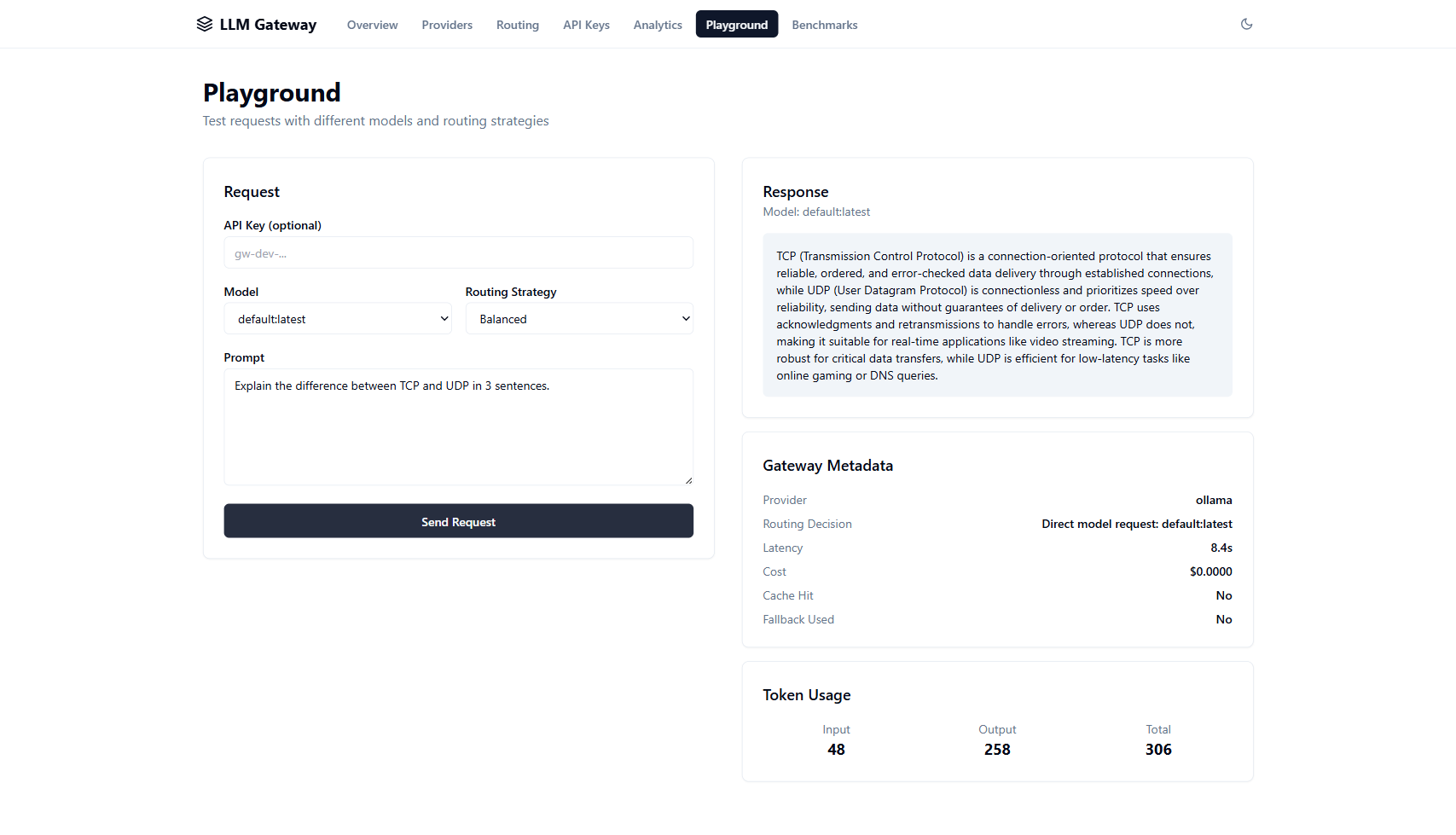
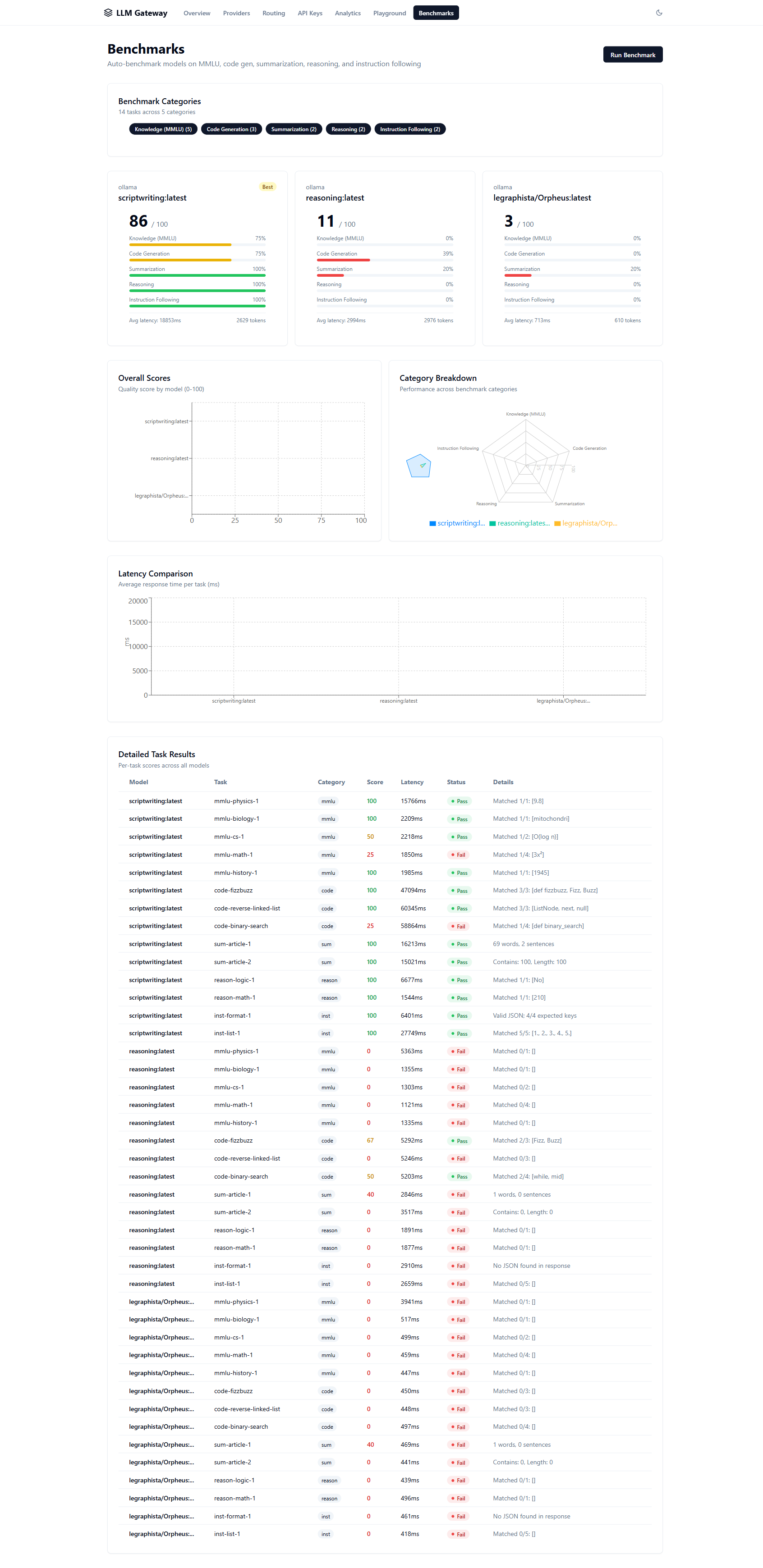
Intelligent multi-provider LLM gateway with cost-optimized routing, semantic caching, automated benchmarking, and real-time observability. Drop-in OpenAI API replacement.
$ git clone https://github.com/aptsalt/llm-gateway.git
$ cd llm-gateway && npm install && npm run dev
$ cd llm-gateway && npm install && npm run dev